From Exploration to Assurance
Autonomous browser testing becomes genuinely difficult the moment the system must decide what actually matters.
Introduction
Most autonomous web testing systems begin with the same architecture:
- crawl pages
- click links
- fill forms
- collect responses
- generate reports
At first, this feels surprisingly powerful.
The engine explores pages autonomously.
It generates traffic.
It captures requests.
It finds occasional issues.
But after enough sessions, a deeper question emerges:
Did the system actually test anything important?
That question changed the architecture of our system entirely.
The result was a transition from:
autonomous exploration
to:
autonomous semantic assurance
This article summarizes the architecture, lessons learned, and major engineering shifts behind that transition.
The First Major Realization
Exploration Is Not Assurance
Initially, the system optimized for exploration efficiency.
The engine rewarded:
- new pages
- new graph nodes
- new templates
- frontier expansion
- novelty
- low-cost progression
This worked extremely well.
Coverage exploded.
Reports became larger and more sophisticated.
But something important was missing.
A run could show:
- 150 actions
- 70 pages
- multiple backend captures
- successful navigation
- replay candidates
while still failing to deeply test the one semantically important form on the site.
This was the first architectural turning point.
Architecture Overview
Autonomous Semantic Testing Architecture
┌──────────────────────────┐
│ Browser Automation Layer │
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ Exploration Engine │
│ - frontier discovery │
│ - navigation │
│ - state expansion │
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ Semantic Extraction │
│ - field roles │
│ - form intent │
│ - environment signals │
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ Flow Classification │
│ - auth │
│ - contact_form │
│ - newsletter │
│ - search │
│ - transactional │
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ Flow Economics │
│ - expected gain │
│ - risk │
│ - novelty │
│ - continuation value │
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ High-Value Assurance │
│ - criticality │
│ - coverage states │
│ - minimum budgets │
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ Backend Capture │
│ - internal writes │
│ - payload extraction │
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ Mutation Planning │
│ - scoring │
│ - replay eligibility │
│ - safety filtering │
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ Controlled Replay │
│ - bounded execution │
│ - same-origin replay │
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ Finding Normalization │
│ - severity │
│ - confidence │
│ - reproducibility │
└─────────────┬────────────┘
│
▼
┌──────────────────────────┐
│ Reporting & Strategy │
│ - executive summaries │
│ - traceability │
│ - assurance visibility │
└──────────────────────────┘
The Shift from Page-Centric to Semantic-Centric Thinking
The biggest architectural evolution was moving away from:
pages
toward:
semantic flows
The system no longer reasons primarily about URLs.
It reasons about intent.
Examples:
| Flow | Semantic Meaning |
|---|---|
| Login form | auth |
| Email subscription | newsletter |
| Search box | search |
| Support form | contact_form |
| Checkout endpoint | transactional |
This seems simple conceptually.
In practice, it changes almost every downstream decision:
- exploration prioritization
- replay safety
- mutation depth
- stopping logic
- reporting
- retry behavior
- business relevance
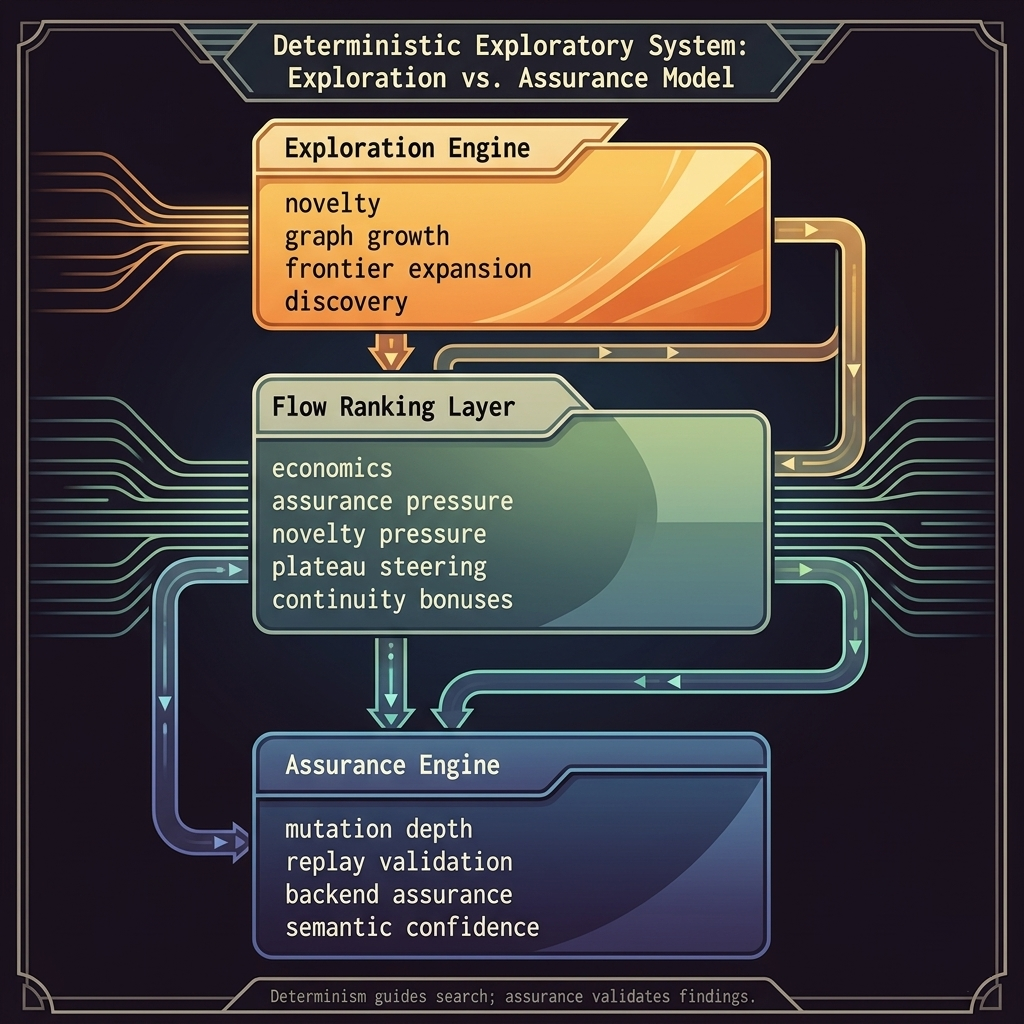
Exploration vs Assurance
One of the most important discoveries was that autonomous testing actually contains two competing systems.
Exploration Engine
Optimizes for:
- novelty
- graph growth
- coverage
- frontier expansion
- low-cost discovery
Assurance Engine
Optimizes for:
- confidence
- replayability
- mutation depth
- semantic importance
- reproducibility
- validation quality
Exploration vs Assurance Model
┌─────────────────────┐
│ Exploration Engine │
│---------------------│
│ novelty │
│ graph growth │
│ frontier expansion │
│ discovery │
└─────────┬───────────┘
│
▼
┌──────────────────────┐
│ Flow Ranking Layer │
│----------------------│
│ economics │
│ assurance pressure │
│ novelty pressure │
│ plateau steering │
│ continuity bonuses │
└─────────┬────────────┘
│
▼
┌─────────────────────┐
│ Assurance Engine │
│---------------------│
│ mutation depth │
│ replay validation │
│ backend assurance │
│ semantic confidence │
└─────────────────────┘
If exploration dominates completely:
the system behaves like a crawler.
If assurance dominates completely:
the system gets stuck retrying a few flows forever.
Balancing these forces became one of the hardest engineering problems in the project.
Plateau Logic Accidentally Hid Important Failures
The engine eventually became very good at detecting:
- repeated low-yield flows
- frontier starvation
- plateau conditions
- no-new-destination states
Initially this improved efficiency significantly.
But it introduced a subtle failure mode:
semantically important flows could be abandoned too early.
For example:
- contact forms
- auth flows
- state-changing endpoints
might receive only shallow testing before exploration economics shifted attention elsewhere.
The reports looked active.
But assurance was weak.
This led to the introduction of:
High-Value Semantic Flow Assurance
High-Value Flow Assurance
Flows now receive:
- canonical category
- semantic criticality
- assurance budgets
- completion states
- plateau resistance
Semantic Flow Lifecycle
Detected
│
▼
Submitted
│
▼
Backend Observed
│
▼
Mutation Generated
│
▼
Replay Eligible
│
▼
Replay Executed
│
▼
Validated
│
▼
Completed
Exceptional states:
Blocked
Validation Failure
Submit No Effect
Environment Hostile
This lifecycle became more important than raw page exploration.
Environment Classification Became Necessary
Another major lesson:
many apparent testing failures were actually environment failures.
The engine encountered:
- Cloudflare challenges
- human verification gates
- auth redirects
- unstable navigation surfaces
- partial rendering environments
- anti-bot protections
Without explicit environment modeling, reports became misleading.
For example:
exploration failed
might really mean:
interaction_hostile
or:
unstable
Environment Classification Pipeline
Environment Detection
│
▼
┌────────────────────┐
│ accessible │
│ auth_required │
│ interaction_hostile│
│ unstable │
│ partial │
│ blocked │
└─────────┬──────────┘
│
▼
Environment Strategy Resolver
│
▼
Retry Eligibility
│
▼
Controlled Retry
│
▼
Final Classification
This dramatically improved report trustworthiness.
Replay Safety Became More Important Than Replay Volume
Early mutation systems aggressively replayed everything.
This generated activity.
It did not generate trust.
The current architecture is intentionally conservative.
Fields are classified semantically:
| Field | Role |
|---|---|
| user_input | |
| csrf_token | security_token |
| action | routing_action |
| hp_email | honeypot_or_anti_spam |
| page_url | tracking_context |
Replay eligibility depends heavily on these roles.
This reduced noisy findings dramatically.
One major lesson:
The best autonomous mutation systems are often highly selective systems.
Mutation Safety Pipeline
Captured Request
│
▼
Field Role Classification
│
▼
Mutation Scoring
│
▼
Replay Eligibility
│
▼
Safety Filtering
│
▼
Controlled Replay
│
▼
Finding Classification
│
▼
Severity & Confidence Normalization
This pipeline turned out to be far more valuable than brute-force replaying.
Reporting Became an Engineering Problem
At some point the reports became too technically rich.
They included:
- frontier economics
- graph growth
- novelty scores
- steering telemetry
- candidate rankings
- plateau metrics
Technically useful.
Humanly exhausting.
Eventually we realized:
The report should answer business questions first.
Not engine questions.
The Most Valuable Report Surface
The most useful report section became:
High-Value Flow Coverage
| Flow | Criticality | Coverage State | Backend Seen | Replay | Findings |
|---|---|---|---|---|---|
| Contact Form | High | mutation_generated | Yes | No | application_error_response |
| Newsletter | Medium | submitted | Yes | No | None |
| Search | Low | completed | No | No | None |
This created far more trust than raw telemetry.
One Unexpected Lesson:
Semantic Contradictions Destroy Trust
At one point reports showed:
Environment: accessible
Environment Strategy: aborted_before_exploration
Recorded Actions: 149
Technically this happened because preflight degraded while exploration later continued.
But semantically the report contradicted itself.
Humans noticed immediately.
This became one of the most important lessons in the project:
Autonomous systems are trusted through semantic coherence, not raw technical correctness.
The System Is No Longer a Crawler
The system now reasons about:
- semantic importance
- assurance depth
- replay safety
- environment hostility
- retry eligibility
- mutation value
- coverage progression
- reproducibility
- business relevance
At this point, the architecture behaves much more like:
an autonomous semantic testing system
than:
a crawler with testing features
Final Observation
The original question was:
How many pages did we explore?
The current question is:
Did we autonomously spend enough effort on the things that actually matter?
That single shift changed almost the entire architecture.


